Lets Write Database from Scratch

Table of Contents
Overview
Databases, we hear about them everywhere. They're crucial for efficiently storing, retrieving, and managing data. I've used databases a lot throughout my journey as a developer, but every now and then, I’d find myself wondering, how the hell does this thing actually work?
To be honest, until now, I just had that curiosity but still moved on. But last night, I had one of those moments where I thought, Hey, I know a bit of Rust (not an expert), so why not try building one? This project will be a great excuse to dive deeper into Rust and, more importantly, to finally understand how databases work under the hood. Plus, let's be real, I can brag about it to my friends and maybe sneak it into my resume too 😉.
The Implementation Plan
So here’s the deal: I have zero idea how databases work internally at the moment. I’ve browsed through some tutorials and blogs, and there’s a ton of great stuff out there. But this project isn’t about copying someone else's work—it's about learning. For this I will only refer to the SQLite docs and the Rust standard library docs.
Keep in mind, we are not trying to build a fully-fledged, production-ready database here. This will be a toy database for the sole purpose of learning. Below are the features I plan to implement:
- Create/Delete databases
- Create/Alter/Delete tables
- Select/Insert/Update/Delete data in the table
- Transaction support with Begin/Commit/Rollback
- Indexing and data persistence
- ACID compliance (Atomicity, Consistency, Isolation, Durability)
- Allowing access to the database over the network
- Maybe JOIN, WHERE (
not sure yet!) - And yes, we might refer to syntax from
mysqlas well
Oh, and I just realized—I haven’t named the database yet. Let’s call it bhu_db. Simple, easy to remember, and it kind of has a nice ring to it.
Crawling the SQLite Docs
Alright, so before we get our hands dirty with code, We need to do some research. I decided that my primary source of reference will be the SQLite docs. It’s a goldmine of information, and since SQLite is lightweight and easy to understand, it's perfect for our use case.
After looking for the right part finnaly got the document that I wanted; "Architecture of SQLite". Below is the image that I just screenshotted from there and this gives us a clear components that we need to build, but I will cut corners probably, I am not sure yet.
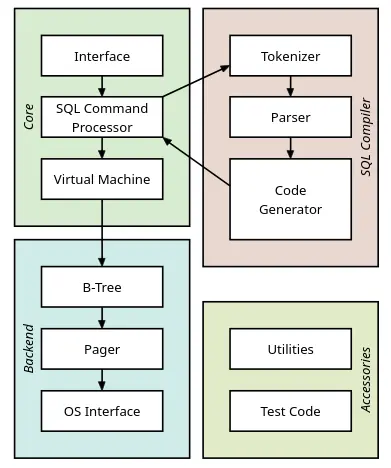
Ok, got what we need, we will start from top to bottom that is from Interface and then go downwards into the core components.
Coding Plan
The database will use a client-server architecture, but for time being we will use a simple REPL (Read-Eval-Print Loop) until we implement the networking protocol between the client and server. The image below describes the initial work plan, as well as the end goal as I continue building it.

In short, the REPL will serve as the interface between the user and the database(backend) for the time being. The user input will be tokenized, parsed, and processed, resulting in the final output.
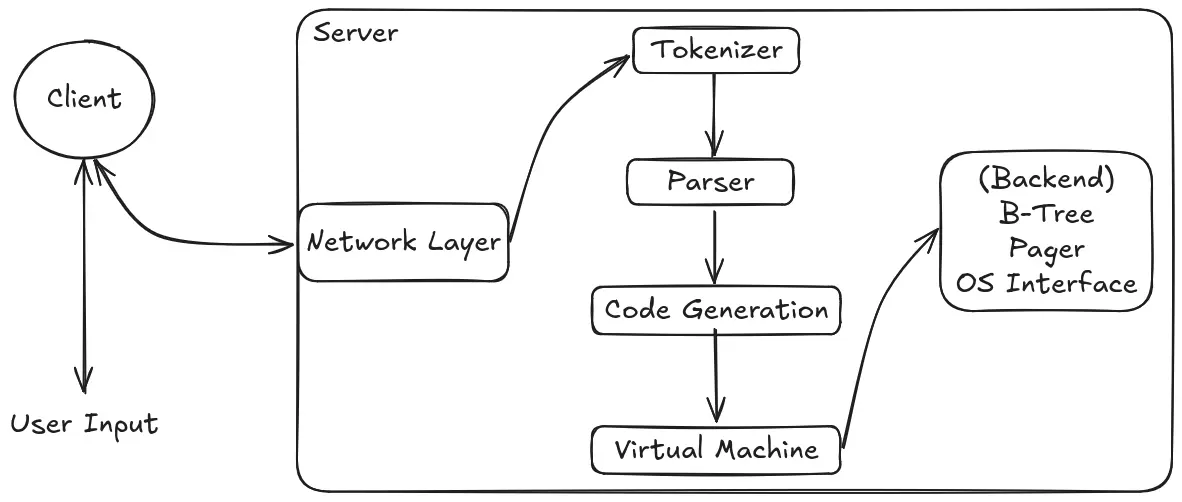
As I keep building, the plan is to eventually allow users to connect to the database server using a client. The server will expose a TCP port and listen for user input through a simple protocol that I will implement. The rest of the architecture will remain the same as the initial plan, and finally, the user will receive the query results through network.
Ok, let's fire up the code editor and setup the project.
Getting Started
Alright, before diving into the code, we need to set up a solid foundation. This will be our first step in building bhu_db.
Pre-requisites
Make sure you have Rust installed. You can install Rust by following the instructions from the official Rust website.
Project Initialization
We'll use Cargo to initialize a library project (which does not contain a main function by default). This project will also include a couple of binary targets (each containing its own main function) within the same project.
cargo new bhu_db --lib
cd bhu_db
# You should see the following structure:
tree
.
├── Cargo.toml
└── src
└── lib.rs
Initial Files and Folder Setup
The core components like the Tokenizer, Parser, and other database-related code will be in the library (lib.rs). The server, client, and REPL components will be implemented as separate binaries. In Rust, we can achieve this by creating a bin folder inside the src directory. Here’s how to set it up:
mkdir -p src/bin/repl && touch src/bin/repl/main.rs
mkdir src/bin/client && touch src/bin/client/main.rs
mkdir src/bin/server && touch src/bin/server/main.rs
# The folder structure should look like this:
.
├── Cargo.toml
└── src
├── bin
│ ├── client
│ │ └── main.rs
│ ├── repl
│ │ └── main.rs
│ └── server
│ └── main.rs
└── lib.rs
Now, with this setup, you can run each binary target using the command:
cargo run --bin <repl/client/server>
Alright, this concludes our initial file and folder setup. Now, it’s time to start coding!
Simple REPL
A REPL (Read-Eval-Print Loop) is an interactive environment where user inputs are read, evaluated, and the results are printed back to the user. For our database, we need a simple loop that will run indefinitely, wait for user input, and take actions based on that input. For example, we'll exit the loop (break the loop) when the user types exit. Here’s how we can achieve that by editing the src/bin/repl/main.rs file:
use std::{io::{self, Write}, process};
const WELCOME_MSG: &str = r#"
.______****__****__***__****__******_______**.______***
|***_**\**|**|**|**|*|**|**|**|****|*******\*|***_**\**
|**|_)**|*|**|__|**|*|**|**|**|****|**.--.**||**|_)**|*
|***_**<**|***__***|*|**|**|**|****|**|**|**||***_**<**
|**|_)**|*|**|**|**|*|**`--'**|****|**'--'**||**|_)**|*
|______/**|__|**|__|**\______/*****|_______/*|______/**
*******************************************************
Welcome to bhu_db!
Type 'exit' to quit.
"#;
fn main() {
println!("{}", WELCOME_MSG);
let mut stdout = io::stdout();
let stdin = io::stdin();
loop {
print!("bhu_db> ");
stdout.flush().unwrap();
let mut input = String::new();
let _ = stdin.read_line(&mut input).unwrap();
let input = input.trim();
match input {
"exit" => {
println!("Exiting bhu_db...");
process::exit(0);
},
_ => {
println!("Unrecognized command: '{}'", input);
continue;
}
}
}
}
In the code above:
- Handles to
stdoutandstdin:- We need a handle to
stdoutto print to the console and a handle tostdinto read user input.
- We need a handle to
- REPL Loop:
- We enter an
infinite loopwhere we continuously prompt the user with"bhu_db> ". - The
stdout.flush()ensures that our prompt is displayed immediately.
- We enter an
- Reading User Input:
- The line
stdin.read_line(&mut input).unwrap();reads a line from the user. read_lineis a blocking call, meaning it will wait until the user pressesEnter.
- The line
- Processing the Input:
- We trim the input to remove any leading or trailing whitespace.
- If the user types
"exit", the program prints a message and exits usingprocess::exit(0). - For any other input, we print a message saying the command is unrecognized (just for now) and continue the loop.
We can test the REPL by running:
cargo run --bin repl
# The result should look like the below
.______****__****__***__****__******_______**.______***
|***_**\**|**|**|**|*|**|**|**|****|*******\*|***_**\**
|**|_)**|*|**|__|**|*|**|**|**|****|**.--.**||**|_)**|*
|***_**<**|***__***|*|**|**|**|****|**|**|**||***_**<**
|**|_)**|*|**|**|**|*|**`--'**|****|**'--'**||**|_)**|*
|______/**|__|**|__|**\______/*****|_______/*|______/**
*******************************************************
Welcome to bhu_db!
Type 'exit' to quit.
bhu_db> create database test;
Unrecognized command: 'create database test;'
bhu_db> exit
Exiting bhu_db...
This REPL will form the basis of our interaction with bhu_db for now, but as we continue, we'll extend it to handle more complex commands and eventually switch to a client-server model.
Lexer
The process of breaking down input text into smaller, meaningful pieces is called Lexical Analysis, but you might also hear it referred to as Tokenization or Scanning. Regardless of the name, the idea is the same: we take the user's input, examine it character by character, and group those characters into meaningful units called tokens. These tokens are essential for the next stages of processing.
SELECT column1, column2 FROM some_table;
Here, how we interpret it:
SELECTis a keyword with a predefined meaning, it tells the database to retrieve data.FROMis another keyword, specifying the source of the data.column1,column2, andsome_tableare identifiers, they don’t have predefined meanings, but they provide context to the keywords (e.g., what to select and from where).;is asymbol, specifying the end of query.- Any numbers, strings, or boolean values within queries (e.g.,
123,'text',TRUE) are referred to as literals.
The job of the lexer is to scan through the input one character at a time, grouping them into lexemes aka the smallest sequences of characters that represent something meaningful. For our query, the lexemes are:
SELECT,column1,cloumn2,FROM,some_tableand;
Tokens and Token Types
The lexer takes the raw input and groups characters into lexemes, which are the smallest meaningful sequences of characters. It then assigns a token type to each lexeme. While lexemes are just raw fragments of the input text, a token combines a lexeme with additional information, such as its type or position in the source. For example, in the query above:
- Lexeme:
SELECT→ Token:Keyword(SELECT) - Lexeme:
column1→ Token:Identifier(column1) - Lexeme:
;→ Token:Symbol(Semicolon)
Each token has:
- Lexeme: The actual text from the input.
- Token Type: What kind of token it is (e.g., keyword, identifier, literal, or symbol).
- Metadata: Additional information, such as the token’s position in the input.
This transformation from characters to tokens is a critical first step in building a database or any system that processes user inputs.
Recognizing Keywords, Identifiers, and Literals
- Keywords: The lexer recognizes predefined keywords like
SELECT,FROM,WHERE, etc., which have special meanings. - Identifiers: Any user-defined names (e.g., column or table names) that don’t match a keyword fall into this category.
- Literals: These include numbers, strings, and boolean values. For example:
123→Literal(Number, 123)'hello'→Literal(String, 'hello')TRUE→Literal(Boolean, TRUE)
Why is Lexical Analysis Important?
The lexer does more than just grouping characters. It filters out irrelevant details like whitespace and comments, normalizes tokens for easier parsing, and helps identify syntax errors early. For example; a misspelled keyword like SELEC would be flagged as an unrecognized lexeme.
By the end of this process, the input query is transformed into a structured list of tokens, ready for further processing by the parser.
Coding the Lexer
Now that we’ve covered the basics of a lexer, it’s time to start implementing it. We’ll follow a step-by-step approach to ensure everything is well-structured and easy to understand.
Setting Up the Project Files and Folders
Let’s first organize our project folder. Update your src/lib.rs file to declare the lexer module:
// src/lib.rs
mod lexer
Next, create the necessary folders and files for the lexer module:
mkdir src/lexer && touch src/lexer/mod.rs src/lexer/token_type.rs src/lexer/token.rs src/lexer/lexer.rs
Here’s what each file will contain:
- src/lexer/mod.rs : Handles module declarations for the lexer.
- src/lexer/token_type.rs: Defines all token types (e.g., keywords, symbols, literals).
- src/lexer/token.rs: Defines the structure for a token, including metadata like line and column number.
- src/lexer/lexer.rs: The main logic of the lexer, responsible for converting input into tokens.
Add the following to src/lexer/mod.rs to declare all submodules:
pub mod token_type;
pub mod token;
pub mod lexer;
Defining Token Types
Tokens represent the smallest meaningful units in a query, and each token has a type (e.g., keyword, symbol, literal). Let’s define these types in src/lexer/token_type.rs.
// src/lexer/token_type.rs
use std::fmt;
#[derive(Debug)]
pub enum TokenType {
// Keywords
DATABASE, DATABASES, TABLE, TABLES, SHOW, DESCRIBE, DROP,
CREATE, UPDATE, INSERT, SELECT, DELETE, ALTER, INTO, VALUES, SET, ADD,
FROM, WHERE, AND, OR, IS, NOT, NULL, ORDER, BY, ASC, DESC,
LIMIT, AS, LIKE, IN, BETWEEN, JOIN, INNER, LEFT, RIGHT, CROSS, ON,
UNION, ANY, ALL, GROUP, HAVING, EXISTS, MODIFY,
CASE, WHEN, THEN, ELSE, END, SOME, VIEW,
//Functions
MIN, MAX, COUNT, AVG, SUM, IFNULL, COALESCE,
//Constraints
CONSTRAINT, UNIQUE, PRIMARY, FOREIGN, KEY, CHECK, DEFAULT, INDEX,
REFERENCES, AUTO_INCREMENT,
//Symbols and Operators
UNDERSCORE, COMMA, SEMICOLON, LEFTPAREN, RIGHTPAREN,
PLUS, MINUS, DIVIDE, PERCENT, ASTERISK, BWAND, BWOR, BWXOR,
EQUAL, GREATERTHAN, LESSTHAN, GREATEREQUAL, LESSEQUAL, NOTEQUAL,
PLUSEQUAL, MINUSEQUAL, ASTERISKEQUAL, DIVIDEEQUAL, PERCENTEQUAL, BWANDEQUAL, BWEXCEQUAL, BWOREQUAL,
// Misc
VARCHAR, INT, FLOAT, DATE, IDENTIFIER,
EOF,
}
#[derive(Debug)]
pub enum Literal {
StringLiteral(String),
NumberLiteral(isize),
FloatLiteral(f64),
BooleanLiteral(bool),
NullLiteral,
}
impl fmt::Display for Literal {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
match self {
Literal::StringLiteral(s) => write!(f, "{}", s),
Literal::NumberLiteral(n) => write!(f, "{}", n),
Literal::FloatLiteral(fl) => write!(f, "{}", fl),
Literal::BooleanLiteral(b) => write!(f, "{}", b),
Literal::NullLiteral=> write!(f, "Null"),
}
}
}
Here, we just copied all the different token type that are available, which is here just for an example, so that we can get the gist of how things are done. We also implemented Display trait so that we can print the Literal value and would be useful for debugging purpose.
Defining Token Structure
With the token types defined, we can now create a structure to represent a single token. Each token will include its type, lexeme, and metadata (like the position in the input).
// src/lexer/token.rs
use super::token_type::{Literal, TokenType};
use std::fmt;
#[derive(Debug)]
pub struct Token {
token_type: TokenType,
lexeme: String,
literal: Option<Literal>,
line: usize,
column: usize,
}
impl Token {
pub fn new(
token_type: TokenType,
lexeme: String,
literal: Option<Literal>,
line: usize,
column: usize,
) -> Self {
Token {
token_type,
lexeme,
literal,
line,
column,
}
}
}
impl fmt::Display for Token {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
let literal_display = match &self.literal {
Some(lit) => format!("{}", lit),
None => "None".to_string(),
};
write!(
f,
"Token {{
type: {:?},
lexeme: '{}',
literal: {},
line: {},
column: {}
}}",
self.token_type, self.lexeme, literal_display, self.line, self.column
)
}
}
Here's what each field means:
- token_type: The type of the token (e.g., keyword (TokenType::TABLE ...), symbol (TokenType::COMMA ...), literal (TokenType::VARCHAR ...)).
- lexeme: The actual text that is parsed from the user input which forms this token.
- iteral: Optional literal value for tokens that represent values (e.g., numbers or strings).
- line and column: Metadata to track the token’s position in the input for error reporting.
With the foundational components of the lexer in place, the next step is to implement the actual logic for reading input and generating tokens
The Lexer
The lexer is the first major component of our database. It processes the raw input string, breaking it down into manageable pieces called tokens. These tokens represent meaningful units like keywords, identifiers, symbols, or literals. Let us start by defining the structure for the lexer and implement a associated method to create the instance of Lexer:
use super::token::Token;
use std::{iter::Peekable, str::Chars};
pub struct Lexer<'a> {
source: Peekable<Chars<'a>>,
tokens: Vec<Token>,
current: usize,
line: usize,
start: usize,
errors: Vec<String>,
}
impl<'a> Lexer<'a> {
pub fn new(source: &'a str) -> Self {
Lexer {
source: source.chars().peekable(),
tokens: Vec::new(),
current: 0,
line: 1,
start: 0,
errors: Vec::new(),
}
}
}
Here's what each field means:
- source: Peekable iterator of characters, so that the lexer can inspect upcoming characters to decide how to group them into tokens, making it both efficient and flexible.
- tokens: Container to store tokens that will be generated as we tokenize the input.
- current: Track the current position of the lexer.
- line: Metadata to track the lexer's position in the input for error reporting.
- start: Track the start position of current token, where current will be at end, and then we can extract the actual characters from input.
- errors: List of errors so we can inform the user of multiple error at once.
Gut of Lexer
Now that we have foundation for our lexer,